Modern microscopy frequently generates image data in the GB-TB range. Such data cannot be naively opened. First, the data may not fit into the working memory (RAM) of your computer. Second, it would take a lot of time to load the data into the memory. Thus, it is important to know about dedicated concepts and implemenations that enable swift interaction with such big image data.
Prerequisites
Before starting this lesson, you should be familiar with:
After completing this lesson, learners should be able to:
Understand the concepts of lazy-loading, chunking and scale pyramids
Understand some file formats that implement chunking and scale pyramids
Concept map
graph TD
BIG("Big image data") --- RP("Resolution pyramids")
BIG --- C("Chunking")
C --- LL("Lazy loading")
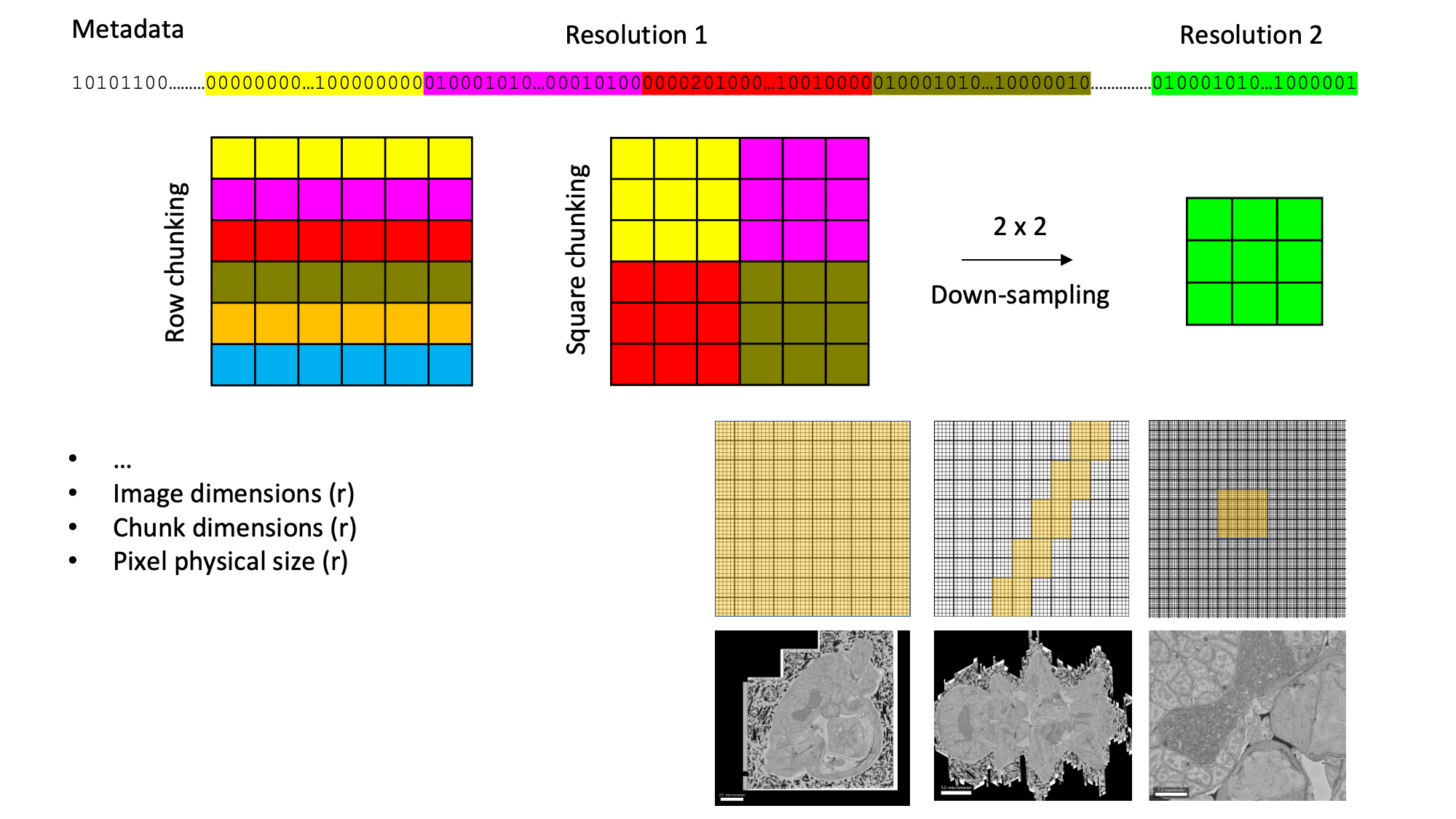
Figure
Big image data formats typically support flexible chunking of data and resolution pyramids. Chunking enables efficient loading of image subregions. Resolution pyramids prevent loading useless details when being zoomed out.
Similarities of big microscopy data with Google maps
We can think of the data in Google maps as one very big 2D image. Loading all the data in Google maps into your phone or computer is not possible, because it would take to long and your device would run out of memory.
Another important aspect is that if you are currently looking at a whole country, it is not useful to load very detailed data about individual houses in one city, because the monitor of your device would not have enough pixels to display this information.
Thus, to offer you a smooth browsing experience, Google Maps lazy loads only the part of the world (chunk) that you currently look at, at an resolution level that is approriate for the number of pixels of your phone or computer monitor.
Chunking
The efficiency with which parts (chunks) of image data can be loaded from your hard disk into your computer memory depends on how the image data is layed out (chunked) on the hard disk. This is a longer, very technical, discussion and what is most optimal probably also depends on the exact storage medium that you are using. Essentially, you want to have the size of your chunks small enough such that your hardware can load one chunk very fast, but you also want the chunks big enough in order to minimise the number of chunks that you need to load. The reason for the latter is that for each chunk your software has to tell your computer “please go and load this chunk”, which in itself takes time, even if the chunk is very small. Thus, big image data formats typically offer you to choose the chunking such that you can optimise it for your hardware and access patterns.
Resolution pyramids
If the image data is big and one is zoomed out, the data may have more pixels that the viewing window of your computer monitor. In this case it makes no sense to load all the data, but a lower resolution (down-sampled) version of the same data would give you the same displayed information and, since it is less data, it could be loaded faster. Thus, for big image data one typically saves the data multiple times at different levels of downsampling in a so-called resolution pyramid. If you use appropriate viewing software it will automatically load the data from the appropriate resolution level, depending on your zoom level and the number of pixels of your viewing device. Note that is not only useful for fast visualisation, but can be also handy for image analysis purposes, where certain computations may not need to be performed on the full resolution data.
TIFF files are chunked as planes and as strips within the planes.
One can therefore efficiently lazy load XY planes from a TIFF file. However, in particular lazy loading of YZ planes is very inefficient. The reason is that for typical storage systems (e.g., hard disks) data that resides close together can be swiftly fetched in one read operation. However, data that is distributed must be read in several seek and read operations, which is much slower, because each operation needs time. Note that often it is actually faster to just read everything in one go, even if not all data is needed.
Inspect the size of the file on disk and compare to your computer’s memory
Open the whole file
Observe that this takes some time
Observe that the memory fills up in one go
Lazy-access XY planes
Observe that the memory fills up gradually each time you access a new plane
Try to lazy-access YZ plane
Observe that this likely causes all data being loaded, because TIFF file chunking is not suited for efficiently accessing YZ planes
Show activity for:
ImageJ GUI
Fully load TIFF stack into memory
Check the image file size on disk
Compare this to your computer’s memory
Open Fiji
Use [ Edit > Options > Memory & Threads… ] to see how much memory is accessible to Fiji
Use [ Plugins > Utilities > Monitor Memory… ] to monitor how much memory is currently used
Use [ File > Open ] to open the entire TIFF stack
Observe that this takes time and that the memory fills up
Close the image and observe whether memory is freed
Use [ Plugins > Utilities > Collect Garbage ] to enforce freeing the memory
Lazy load TIFF into standard ImageJ Viewer
Use [ Plugins > Bio-Formats > Bio-Formats Importer ] to lazy open the TIFF stack
Open virtual (<= this is key!)
Observe that initial opening is faster and your memory is not filling up as much
Move up and down along the z-axis
Observe that this is a bit slow because it needs to fetch the data
Observe that your memory fills up while you move
Use [ Image > Stacks > Orthogonal Views ] to look at the data from the side
Observe that now it needs to load all data, because efficiently lazy loading YZ planes from TIFF is not possible, because TIFF files are chunked as XY planes
Lazy load TIFF into BigDataViewer (BDV)
Close all images
Use [ Plugins > Utilities > Collect Garbage ] to free all memory
Make sure to still monitor the memory, using [ Plugins > Utilities > Monitor Memory… ]
Again, use [ Plugins > Bio-Formats > Bio-Formats Importer ] to lazy open the TIFF stack
Open virtual
Now, use [ Plugins > BigDataViewer > Open Current Image ] to view the TIFF stack in BDV
In BDV, use the down arrow key to zoom out (this is necessary for the following )
In BDV, use [ Shift + Y ] to view a XZ plane of the image
Observe that you immediately see something and how the planes are lazy loaded
Observe that not all planes are loaded, but just as many as needed for the current number of pixels of the viewer window and the current zoom level
Use the up arrow keys to zoom in and observe how additional data is being loaded
Key points
“Bio-Formats Importer” with the open virtual option allows you to lazy load XY planes from image data into Fiji
TIFF stacks are chunked as XY planes and within the planes as Y strips; lazy loading planes is typically supported by reader libraries, lazy-loading strips is less supported (and may not be efficient because it may be faster to just load the whole plane anyway).
The ImageJ viewer is blocking; BigDataViewer is not blocking, i.e. you can move around while data is being loaded.
python bioio
# %%
# Open a tif image file
# minimal conda env for this module
# conda create -n ImageFileFormats python=3.10
# activate ImageFileFormat
# pip install bioio bioio-tifffile notebook
#%%
# Load a large tif lazily
frombioioimportBioImageimage_url='https://zenodo.org/records/14857764/files/xyz_uint8__em_platy.tif'bioimage=BioImage(image_url)print(bioimage)print(type(bioimage))#%%
# Extract pixel size
print(f'Pixel size: {bioimage.physical_pixel_sizes}')# Inspect image dimension
print(f'Image dimension: {bioimage.dims}')#%%
# lazy load whole image
bioimage_data=bioimage.dask_dataprint(bioimage_data)#%%
# For actually loading data, first download the data and then load it
frompathlibimportPathimage_path=Path().cwd()/'xyz_uint8__em_platy.tif'bioimage=BioImage(image_path)# load specific image plane
bioimage_data=bioimage.dask_data[:,:,:,10,:].compute()
Open BDV HDF5 with ImageJ BigDataViewer & Bio-Formats
Open 3-D chunked data directly with BigDataViewer
Open Fiji
Use [ Plugins > Utilities > Monitor Memory… ] to keep an eye on the memory
Open xyz_uint8__em_platy__3d_chunk.xml via [ Plugins › BigDataViewer › Open XML/HDF5 ]
Use Shift X, Y, Z to view orthogonal planes
Use the mouse wheel to move along the current axis
Use the arrow keys to zoom
Key observations:
Chunks are lazy-loaded on demand
BDV is non-blocking: One can move around even while data is being loaded
Open 3-D chunked data through Bio-Formats with BigDataViewer
Open Fiji
Open xyz_uint8__em_platy__3d_chunk.xml via drag & drop on Fiji menu bar
The Bio-Format UI will open, select use virtual stack
Use [ Plugins › BigDataViewer › Open Current Image ]
Use Shift X, Y, Z to view orthogonal planes
Key observations:
Compared to abvove, the loading performance is very slow, because Bio-Formats can only lazy load planes, which does not match the 3-D chunking of the data
Open 3-D chunked data multi-resolution data directly with BigDataViewer
Open Fiji
Use [ Plugins > Utilities > Monitor Memory… ] to keep an eye on the memory
Open xyz_uint8__em_platy__3d_chunk_multires.xml via [ Plugins › BigDataViewer › Open XML/HDF5 ]
Key observations:
The viewing performance is improved compared with the above 3-D chunked data that did not have multi-resolution
Open 3-D chunked data multi-resolution data with Bio-Formats
Open xyz_uint8__em_platy__3d_chunk_multires.xml via drag & drop on Fiji menu bar
Key observations:
Since the normal ImageJ viewer does not support multi-resolution data, Bio-Formats asks you to choose one resolution layer
Open BDV HDF5 with python bioio
# %%
# Open a BDV image file
# conda env for this module
# conda create -n bio_io_bdv python=3.10
# activate bio_io_bdv
# pip install bioio bioio-bioformats
# %%
# Load BDV file
# - Observe that BioImage chooses the correct reader plugin
frombioioimportBioImagefrompathlibimportPathbioimage=BioImage(Path().cwd()/'xyz_uint8__em_platy__3d_chunk_multires.xml')print(bioimage)print(type(bioimage))# %%
# load whole data
image_data=bioimage.data# %%
# lazy load data
image_data=bioimage.dask_dataprint(image_data)#%%
# lazy load a specific image plane
bioimage_data=bioimage.dask_data[:,:,:,10,:].compute()#%%
# Checkout different resolution levels
# The way it should be implemented and according to docs
# Get current resolution level
print(bioimage.current_resolution_level)# See all resolution levels
print(bioimage.resolution_levels)# Set resolution level
bioimage.set_resolution_level(0)# The way how it is actually working for this type of image:
# Get current resolution level
print(bioimage.current_scene)# Prints string as combination of image name and resolution level
# See all resolution levels
print(bioimage.scenes)# Set resolution level
bioimage.set_scene(0)# or for scene in bioimage.scenes: bioimage.set_scene(scene)
Create BDV HDF5 with ImageJ
Open Fiji
Open an image of your choice
Use [ Plugins > BigDataViewer > Export Current Image as XML/HDF5 ] to save the image
TODO: Add more information…
Assessment
Fill in the blanks
Opening data piece-wise on demand is also called ___ .
Storing data piece-wise is also called ___ .
In order to enable fast inspection of spatial data at different scales (like on Google maps) one can use ___ .